在 GPT、LLaMA 等大模型的文本生成任务中,采样策略是决定输出结果 “多样性” 与 “准确性” 的核心逻辑。其中Temperature、Top-P、Top-K是常用的三个超参数——三者都围绕“调节生成内容的创意性与确定性”这一核心目标发力,功能方向相近,因此常被混淆;但实际上它们的作用逻辑不同,分别从“概率分布调整”和“候选词筛选”两个维度分工协作,共同塑造模型的生成风格。
一、Temperature:控制概率分布的 “温度旋钮”
Temperature(温度参数)是调整候选词生成概率分布的关键超参数,其作用于模型输出层的 Softmax 函数,通过缩放 logits(模型输出的原始分数)来改变概率分布的 “陡峭程度”。
其数学表达式为:
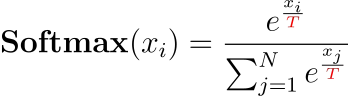
同 Temperature 值的效果差异:
- 当 (T=1):概率分布保持模型原始置信度,生成结果是模型 “最自然” 的输出;
- 当 (T 趋近于 0):概率分布趋近于 “脉冲函数”—— 只有概率最高的 token 会被选中,生成结果高度确定但缺乏多样性;
- 当 (T > 1):概率分布趋于均匀,高概率与低概率 token 的选中概率差距缩小,生成结果更具随机性和创意性(但可能引入无意义内容)。
二、Top-K 与 Top-P:候选词的 “筛选规则”
如果说 Temperature 是 “调整概率的尺子”,Top-K 和 Top-P 则是 “筛选候选词的筛子”—— 它们从已调整的概率分布中,选择部分 token 参与最终采样。
1. Top-K 采样:固定数量的 “前 K 候选”
Top-K 采样的逻辑是从概率排序后的 token 中,固定选择前 K 个作为候选集,仅从这 K 个 token 中进行采样。
- 优势:计算复杂度低,仅需对 token 按概率排序后取前 K 个;
- 局限:灵活性不足 —— 若 K 值过小,会限制生成多样性;若 K 值过大,又可能引入低质量 token;
- 适用场景:需要稳定、低噪声的高质量文本生成(如正式文案、摘要)。
2. Top-P 采样:动态累积的 “概率阈值”
Top-P(也叫 Nucleus Sampling)是一种更灵活的筛选方式:按概率从高到低累加 token 的概率,直到累积概率达到阈值 P,将这些 token 作为候选集。
- 优势:候选集大小随概率分布动态调整 —— 若高概率 token 集中,候选集小;若概率分布分散,候选集大,能更好平衡多样性与质量;
- 局限:计算复杂度略高,需要实时累积概率;
- 适用场景:创意写作、开放对话等需要多样性的场景。
三、Top-K 与 Top-P 的对比
| 特性 | Top-K 采样 | Top-P 采样 |
|---|---|---|
| 选择标准 | 固定选择前 K 个词 | 动态选择累积概率达到 P 的词 |
| 灵活性 | 较低,需手动设置 K 值 | 较高,动态适配候选词数量 |
| 计算复杂度 | 低(仅需排序取前 K) | 较高(需累积概率至阈值) |
| 生成多样性 | 易受限(K 较小时) | 平衡多样性与质量 |
| 适用场景 | 高质量文本、低噪声需求 | 创意写作、开放对话系统 |
四、实际应用:参数组合的技巧
在实际场景中,通常会组合使用 Temperature 与 Top-K/Top-P,以兼顾生成效果:
- 若追求 “精准 + 稳定”:可设置 (T=0.3) + Top-K=20;
- 若追求 “创意 + 灵活”:可设置 (T=0.8) + Top-P=0.9;
- 极端场景(如代码生成):可设置 (T=0.1) + Top-K=5,最大化结果确定性。