大语言模型(LLM)的卓越能力,源于一套成熟的“预训练+微调”训练范式。这一体系融合了自监督、有监督等多种学习方式,还衍生出PPO、DPO等差异化优化路径。本文从基础概念到具体阶段,再到生态差异,全面拆解大模型训练的底层逻辑,厘清各环节的关联与区别。
一、训练的基础:三大学习方式定义与关联
在进入具体训练阶段前,需先明确各学习方式定义,这是理解后续流程的关键:
- 无监督学习:使用无标签数据,模型自主探索数据规律,无需人工标注的正确答案,典型场景如聚类分析、异常检测。
- 有监督学习:依赖带标签(人工标注的正确答案)的数据训练,标签可是情感分类中的“正向/负向”、问答场景中的“标准答案”等,核心是让模型学习“输入→正确输出”的映射关系。
- 自监督学习:数据自身既作为输入又作为监督信号,无需人工标注。预训练阶段的文本预测任务(给定前n个词预测第n+1个词)就是典型的自监督学习——文本片段既是“问题”,也是“标准答案”。
- 半监督学习:“预训练(自监督)+ SFT(有监督)”的组合方式,适用于数据充足但标注资源有限的场景,核心是结合无标注数据的通用规律与标注数据的任务导向。
二、训练阶段全解析:从基础构建到质量优化
大模型训练是循序渐进的迭代过程,核心分为四大核心阶段,不同模型在后续优化阶段存在路径差异:
(一)预训练(Pretrain):自监督学习构建通用知识底座
1. 核心概念
预训练是模型的“启蒙阶段”,采用自监督学习方式,让模型在海量无标注文本中学习人类语言规律与广泛知识,为后续任务适配打下基础。
2. 关键细节
- 数据特征:使用万亿级(t)纯文本数据,涵盖百科、新闻、知乎等多领域完整段落,避免碎片化内容;Llama 3使用15万亿Tokens,约合37.5亿个4000 Token的段落。
- 核心任务:逐字学习人类文字使用方式,吸收大量知识,建立基础语言理解能力与文字表达能力。
- 训练目标:最大化似然函数 ,即让模型准确预测下一个Token的概率分布,最终能计算完整段落的联合概率(所有字符概率的乘积)。
- 段落联合概率的作用:是评估模型学习效果的核心指标,初始随机模型的联合概率极小,训练后逐步提升,可量化模型对语言规律的掌握程度。
- 算力与周期:成本占整体训练的90%以上,Llama 2用2048张A100显卡训练21天,Llama 3的400亿参数模型需16000张H100显卡训练54天。
3. 能力局限
预训练模型虽能流畅续写文本,但存在“接话茬”现象——仅附和对话而非解决问题,无法完成计算、推理等具体任务。根源在于训练数据仅为连续文本,缺乏问答交互式样本,训练目标单一(仅预测下一个词)。
(二)有监督微调(SFT):让模型“会做具体任务”
1. 核心概念
SFT是在预训练基础上,通过有监督学习方式,用少量标注问答数据调整模型参数,让模型从“语言模仿”转向“任务执行”。
2. 关键细节
- 数据特征:数据量级远小于预训练,仅需几十万到100万条问答对(如InstructGPT仅用13k条),格式为“问题+标准答案”,与预训练的连续文本形成鲜明对比。
- 数据来源:早期由人工撰写(如OpenAI雇佣80名博士撰写),现代采用“AI生成+人工筛选”模式降低成本。
- 训练机制:仍采用自回归预测方式,通过特殊分隔符连接问答对,在数据末尾添加终止符,让模型学习停止生成的时机。
- 核心目标:解决预训练模型的“接话茬”问题,让模型理解任务意图,掌握对话、分类、代码生成等具体能力;开源模型常以“instruct”后缀标识完成SFT优化。
3. 局限与衔接
SFT仅能保证模型“会做任务”,但无法确保“做好任务”,回答质量与人类优秀水平仍有差距,需进入后续阶段进一步优化。
(三)奖励模型(Reward Model)
1. 核心概念
奖励模型是独立于主语言模型(如 GPT)的额外训练模型,核心作用是作为评估模型输出的 “教练”,通过学习人类偏好数据建立评分标准,为后续强化学习提供实时反馈,解决 “回答不够好” 而非 “回答错误” 的问题。
2. 完整训练流程
1.前置依赖:需基于完成预训练和 SFT 阶段的模型,依赖其已具备的基本问答能力,为奖励模型生成训练数据打下基础。
2.训练数据生成:
- 准备数万到几十万条 Prompt(覆盖多领域场景),让 SFT 后的模型为每个 Prompt 生成多个 Response(利用模型概率特性产生差异化输出)。
- 核心逻辑:同一问题多次生成可降低数据收集成本,同时确保数据具备质量基础,避免无意义输出干扰训练。
3.标注数据处理(构建偏好数据):
- 标注策略:优先选择排序法(优于直接打分 / 评级),更符合人类判断习惯;每次标注 4 个答案并排序(如 B>A>C>D),可一次性得到 6 条相对关系(B > A、B > C、B > D、A > C、A > D、C > D),提升标注效率。
- 分级优化:Meta 的进阶方案将 “优于” 细分为 4 个等级(显著 > 较好 > 稍好 > 略好),同时引入人工编辑环节,优化首选回答(形成 “edited>chosen>rejected” 的质量层级)。
- 成本控制:采用低成本标注团队(如肯尼亚标注员,日薪约 2 美元),标注 6条数据仅需 2-3 倍单条数据的阅读时间,平衡成本与效率。
4.模型训练执行:
- 输入输出定义:以 “问题 + 模型回答” 为输入,训练模型输出 0-100 分的质量分数,形成量化评估结果。
- 训练目标:让模型输出的分数排序与人类标注的偏好关系一致(如人类标注 D>C>A,则模型给出的分数需满足 D 分 > C 分 > A 分),同时能处理等价情况(如 A=B 表示回答质量相当)。
- 训练本质:模型通过学习标注数据自主寻找评分规律,无预设固定评分模板,通过 “尝试打分方案→验证是否符合人类排序→调整策略” 的迭代过程优化。
3. 核心功能与价值
- 自动化评估:替代人工评估数百万条模型输出数据,解决人工评估的可行性与效率问题。
- 实时反馈支撑:为后续强化学习提供逐字指导的评分信号,让强化学习的 “生成 - 评估 - 优化” 闭环得以落地,这也是借鉴 AlphaGo 强化学习技术在对话领域的创新应用。
(四)强化学习优化:让模型“做好任务”,两大路径差异
这是模型从“合格”到“优秀”的关键阶段,核心是根据奖励模型的评分调整参数,主流分为PPO和DPO两条路径:
1. PPO(近端策略优化):OpenAI的经典方案
- 算法本质:属于强化学习算法,核心是在“保守策略(稳定收益)”与“探索策略(更高收益)”间权衡,通过限制策略更新幅度,避免训练震荡或崩溃。
- 工作流程:模型生成回答→奖励模型打分→PPO算法根据分数调整参数→重复迭代,形成“生成-评估-优化”闭环。
- 迭代机制:当模型进步到奖励模型无法区分优劣时,需重新生成标注数据,训练更强的奖励模型,持续循环优化。
2. DPO(直接偏好优化):LLaMA的创新方案
- 核心差异:直接利用偏好数据(一问两答的优劣对比)优化模型,省去PPO的多轮迭代过程,效率更高。
- 优化目标:同时提升优质答案的联合概率、降低劣质答案的联合概率,类似“奖惩机制”,相比SFT的单方向优化更精细。
- 配套流程:LLaMA采用“六道轮回”循环,完整执行“生成→标注→SFT→DPO”6次,每次用当前最优模型生成新数据,动态更新标注与模型。
3. 拒绝采样(Rejection Sampling):LLaMA的辅助优化
每个问题生成10-30个回答,由奖励模型评分后保留Top3优质回答,30万问题可生成90万条高质量问答对,用于补充SFT数据,进一步提升模型性能。
三、核心技术关联与关键区别
1. 各阶段的递进关系
所有训练阶段均是对同一模型的连续优化:预训练(自监督)打基础→SFT(有监督)教任务→奖励模型定标准→PPO/DPO(强化学习)提质量,形成完整闭环。
2. 关键概念区别
- 自监督vs有监督:自监督的监督信号来自数据本身(如预训练的文本预测),有监督的监督信号来自人工标注(如SFT的问答对)。
- 半监督的本质:是“预训练(自监督)+ SFT(有监督)”的组合,而非独立阶段。
- PPOvsDPO:PPO需通过多轮迭代与奖励模型交互,DPO直接利用偏好数据优化,流程更简洁;两者最终均能实现高质量输出,无代际差距。
四、LLaMA与OpenAI GPT核心差异
从架构设计、训练模式、人类偏好数据收集三大核心维度,拆解两者的底层逻辑差异。
4.1 架构设计
LLaMA与OpenAI(GPT系列)均以Transformer解码器为基础架构,但在“性能-效率-成本”的平衡策略上差异显著,核心差异集中在关键组件优化与开源属性上。
1.架构共性
- 均采用自回归生成模式,专注文本生成、对话等核心任务;
- 依赖多头自注意力机制捕捉长距离语义依赖;
- 通过残差连接解决深层网络梯度消失问题,保障训练稳定性。
2. 核心差异对比
| 对比维度 | OpenAI(GPT系列) | LLaMA系列(LLaMA 2/3) |
|---|---|---|
| 归一化方式 | 后置层归一化(LayerNorm在子层输出后) | 前置层归一化+RMSNorm(计算量减少50%) |
| 激活函数 | GPT-2用ReLU,GPT-3及后续用GELU | 统一使用SwiGLU(复杂语义捕捉能力提升10%-15%) |
| 位置编码 | GPT-2用正弦余弦编码,后续版本未公开 | 旋转位置编码(RoPE),支持128k上下文窗口 |
| 参数规模策略 | 大参数导向(GPT-4超1.8万亿参数) | 小参数高性能(13B优于GPT-3 175B) |
| 开源属性 | 闭源,不公开核心代码与权重 | 开源,公开7B-70B参数权重,支持二次开发 |
| 部署适配性 | 依赖大规模算力,适配云端部署 | 轻量化设计,可在单张V100 GPU运行 |
4.2 训练模式
训练模式是两者最核心的差异,OpenAI为“强化学习+多轮循环”,LLaMA为“拒绝采样+直接偏好优化”
4.2.1 OpenAI的“四阶段标准范式”
OpenAI范式: "预训练→PPO"循环(3-4-3-4轮次结构),遵循“基础能力→任务能力→质量评估→迭代优化”的线性流程,核心是PPO与奖励模型的循环强化:
1.预训练(Pretrain)
- 数据规模:万亿级纯文本(GPT-3超45TB),占整体训练成本90%以上;
- 核心任务:自监督的“预测下一个token”,最大化段落联合概率(
- 目标:构建通用语言与知识基座,掌握文字规律与广泛知识。
2.有监督微调(SFT)
- 数据特征:人工撰写的高质量问答对(早期1.3万条,后期扩展至百万级);
- 核心目标:解决预训练模型“接话茬”问题,让模型理解任务意图而非单纯续写;
- 数据格式:通过特殊分隔符拼接“问题+标准答案”,保留自回归预测机制。
3.奖励模型训练(RM)
- 数据来源:人类标注的“偏好排序数据”(同一问题4-5个回答,人工排序);
- 功能定位:独立于主模型的“教练”,输出0-100分质量评分,确保排序与人类一致;
- 标注成本:早期雇佣80名博士标注,后期引入肯尼亚标注团队(日薪2美元)。
4.强化学习优化(PPO)
- 核心流程:模型生成回答→RM打分→PPO算法调整参数,强化高分回答;
- 循环机制:需3-4轮“RM训练→PPO优化”,GPT-4仅PPO阶段消耗超10万张GPU小时;
- 局限性:依赖RM评分质量,若RM无法区分优劣则进入性能瓶颈。
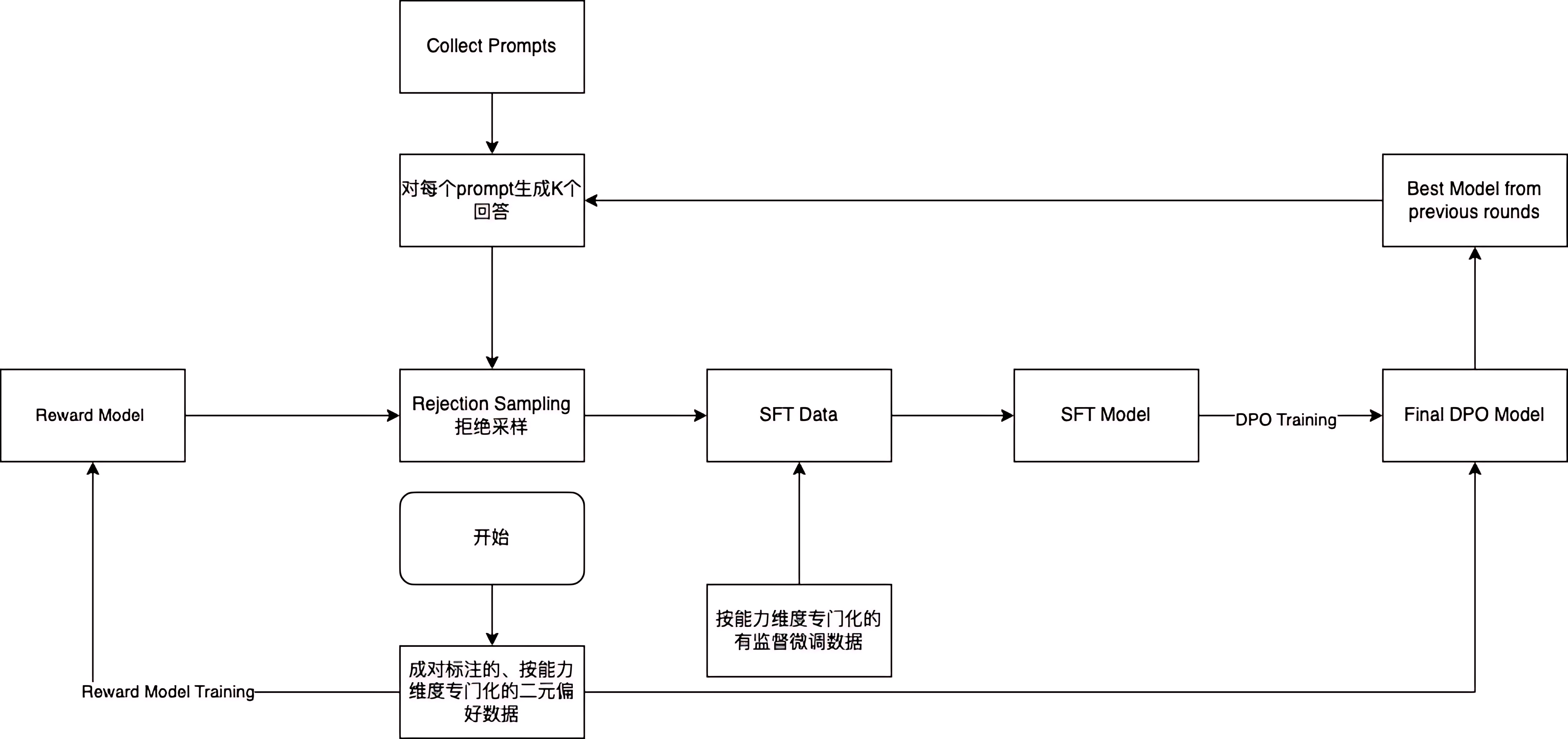
4.2.2 LLaMA的“六轮循环创新范式”(LLaMA 2/3)
LLaMA范式: "预训练→DPO"循环(2-3-4-5轮次结构),以“偏好数据”为核心,通过“拒绝采样+DPO”简化强化学习:
1.预训练(Pretrain)
- 数据规模:LLaMA 3使用15万亿Token(约37.5亿个段落),聚焦公开来源数据;
- 目标与OpenAI一致,但通过“更多公开数据”弥补参数规模劣势,训练成本仅为GPT-3的1/20。
2.奖励模型训练(RM)
- 差异点:早于SFT介入,基于预训练模型生成回答;
- 标注维度:人工标注“显著优于/好/较好/略微好”四级排序,比OpenAI更精细。
3.拒绝采样(Rejection Sampling)
- 核心创新:每个问题生成10-30个回答→RM评分→保留Top 3优质回答;
- 效果:数据利用率提升3倍,单条数据质量接近人工撰写的90%,LLaMA 3通过该步骤生成90万条优质问答对。
4.有监督微调(SFT)
- 数据构成:拒绝采样筛选的优质回答(70%)+人工修正数据(30%);
- 训练效率:LLaMA 3 SFT阶段仅需1600张H100 GPU运行5天,数据量为预训练的1/5000。
5.直接偏好优化(DPO)
- 核心创新:替代PPO的轻量优化方式,无需复杂强化学习流程;
- 原理:提升“好回答”的联合概率,降低“差回答”的概率,类似“奖惩机制”;
- 优势:计算量比PPO减少60%,代码生成任务性能追平GPT-4。
6.六轮循环迭代
-
机制:每完成“RM→拒绝采样→SFT→DPO”一次,用优化后的模型生成新数据重复流程;
-
验证:Meta实验显示6轮后性能达峰值,第7轮提升不足5%,固定为“六道轮回”。
4.2.3 训练模式核心差异总结
| 对比维度 | OpenAI(GPT系列) | LLaMA系列 |
|---|---|---|
| 核心优化技术 | PPO(近端策略优化,依赖强化学习) | DPO(直接偏好优化,无需强化学习) |
| 数据成本 | 高(单模型标注成本超1亿美元) | 低(AI生成+人工筛选,成本降为1/5) |
| 训练循环机制 | “RM→PPO”3-4轮线性循环 | “RM→拒绝采样→SFT→DPO”6轮闭环迭代 |
| 性能突破方式 | 增大模型参数规模 | 优化数据质量(拒绝采样筛选优质样本) |
| 可复现性 | 闭源,无法复现训练过程 | 开源,公开数据来源与训练代码,可复现 |
4.3 人类偏好数据收集
人类偏好数据是模型“对齐人类期望”的核心,两者均遵循“一个问题→多个回答→人类排序”的核心逻辑,但在收集方式、成本控制上存在差异。
1. 通用收集逻辑
- 核心形式:避免精准打分的主观性,采用“排序标注”(如B>A>C>D);
- 数据利用率:4个回答排序可生成6条相对关系,大幅提升训练样本量;
- 核心目标:捕获人类对回答“全面性、严谨性、深度”的主观评价标准。
2. 具体收集方式差异
| 对比维度 | OpenAI(GPT系列) | LLaMA系列 |
|---|---|---|
| 回答生成数量 | 每个问题生成4-5个回答(基于SFT模型) | 每个问题生成10-30个回答(基于预训练/RM模型) |
| 标注维度 | 早期二分类(好/差),后期三级排序(好/中/差) | 四级细分+人工编辑优化(edited>chosen>rejected) |
| 成本控制策略 | 高薪博士团队→肯尼亚低薪标注员(日薪2美元) | AI生成→RM初筛→低薪标注→专家抽检(成本为1/10) |
| 数据规模 | GPT-4 RM阶段约33万条偏好数据 | LLaMA 3 RM阶段约100万条(含6轮循环新增数据) |
| 工具支持 | 自研标注平台,人工逐句阅读排序 | 自动化工具(高亮差异),标注效率提升2倍 |
3. 行业实践案例
- MID Journey(文生图工具):生成4张低清预览图→用户选择偏好图生成高清版→选择行为即为偏好数据,支撑5亿美元年收入;
- ChatGPT:通过“哪个回答更好”反馈按钮收集用户偏好,每天产生超10亿条反馈数据;
- LLaMA开源社区:通过“用户贡献聊天记录”模式,让用户成为免费标注师,降低数据成本。
五、总结
大模型训练的核心逻辑是“数据驱动+人类反馈”:用万亿级数据通过自监督学习构建预训练底座,用少量标注数据通过有监督学习教会模型做任务,再用人类偏好数据训练奖励模型,最后通过PPO或DPO优化回答质量。
开源生态与OpenAI的路线差异,本质是成本与灵活性的权衡——开源模型通过合成数据、用户贡献数据降低成本,提供高灵活性;OpenAI通过付费标注、闭源优化保证数据质量与性能,提供开箱即用的服务。两者虽路径不同,但均能实现顶尖水平,共同推动大模型技术的落地与迭代。